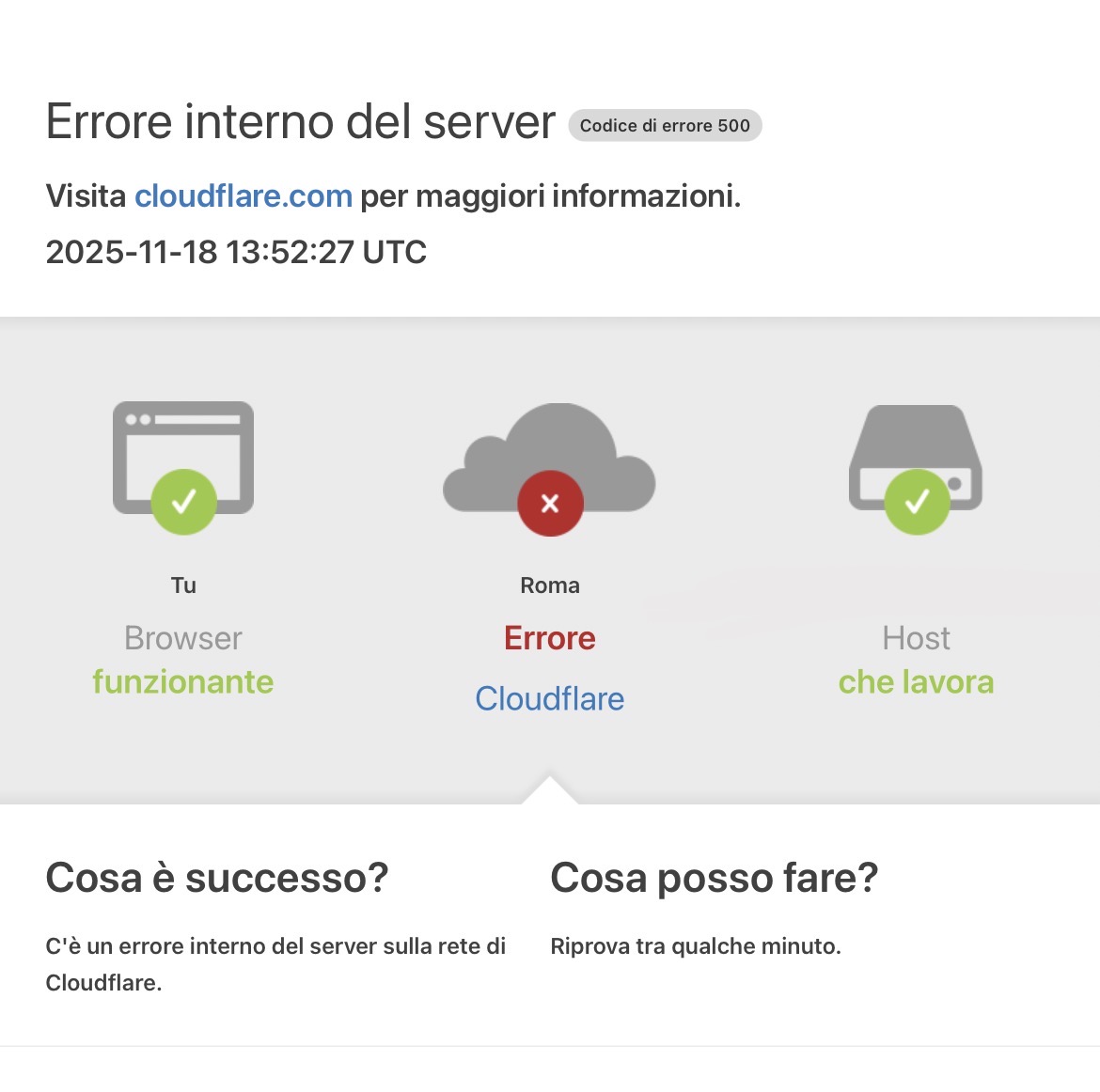
This morning, November 18, 2025, a huge part of the Internet simply stopped, Cloudflare is still Down (check the status from here). Pages that wouldn't load, 500 errors everywhere, inaccessible social media, even the sites meant to monitor outages went down. At the center of the storm is Cloudflare, the infrastructure giant that protects, accelerates, and routes a huge portion of the world's traffic.
What happened to the Cloudflare network
According to initial reports, the problems started around 6:30–6:40 AM on the US East Coast, when thousands of users began seeing 500 errors on very different sites: X (formerly Twitter), ChatGPT, Canva, public transport services, and various high-traffic platforms. Reports on tools like Downdetector rose rapidly, exceeding thousands of reports within minutes.
Cloudflare almost immediately confirmed the existence of a global issue, speaking of "widespread 500 errors" and difficulties even on its own Dashboard and APIs. As the morning progressed, the company stated it had identified the internal cause of the outage and was working on a fix, while monitoring charts showed a slow decline in errors, but levels still higher than normal.
Sponsored Protocol
Why the outage of a single provider halts half the Web
Cloudflare is not just another service: it is one of the central hubs of the modern Internet. It acts as a CDN, reverse proxy, web application firewall, DNS, and anti-DDoS protection for over 20% of the world's sites by some estimates. When such a central point has a problem, the effect is not local but cascading: tens of thousands of domains start returning server errors, even if their origins are perfectly functional.
For the end user, the result is always the same: "the site is down." But behind that message lies an architecture breaking at the point where everyone had decided to simplify their lives: delegating security, caching, intelligent routing, and attack protection to Cloudflare. As long as everything works, it's extremely convenient. When something goes wrong, you realize you've put many eggs in one basket.
Sponsored Protocol
What we know (and what we don't) about the causes
At the time of writing, Cloudflare speaks of an "internal service degradation" issue and an unusual traffic spike that overwhelmed part of the routing system. There are no clear indications it was an attack, and everything suggests an internal incident rather than a targeted external action, although investigations are still ongoing.
It wouldn't be the first time: the company has previously published detailed analyses of similar incidents, from the issue with the public DNS 1.1.1.1 to the Dashboard and API blockage caused by configuration errors that lay dormant for weeks before exploding. Recent history makes one thing clear: you don't necessarily need spectacular attacks to jam a global infrastructure; configuration errors in the wrong places are enough.
Who was left offline and what it meant in practice
The effects did not hit just one sector. Beyond the most visible social media and digital services, local transport systems, institutional sites, SaaS platforms, and productivity tools experienced difficulties. Even Downdetector, the service that tracks others' outages, had problems and at times was unreachable precisely because it relies on Cloudflare.
Sponsored Protocol
For companies, this translated into calls to IT teams, overwhelmed customer chats, blocked e-commerce, and inaccessible dashboards. It didn't matter how healthy the origin server was: if the entry point was Cloudflare, for the user, everything was down. The incident also affected Cloudflare itself, with difficulties accessing the management panel and APIs, complicating life for those who should have reacted most quickly.
The architectural lesson: dependency, redundancy, plan B
This outage is yet another reminder of a theme well-known to those working with hosting and infrastructure: risk concentration. Relying on a single large provider for DNS, CDN, proxy, firewall, and perhaps even zero-trust rules is convenient, but it creates a single point of failure very difficult to bypass in an emergency.
Sponsored Protocol
Countermeasures are not trivial, but they exist. Multi-DNS with different providers, emergency plans to temporarily bypass the proxy, multi-CDN strategies for the most critical projects, independent monitoring that doesn't depend on the same entity having problems. It's more complex to design, but it's also the only way to prevent a single company from making your business invisible for hours on its own.
What companies, developers, and sysadmins should do now
Immediately, the priority is to check the status of the services you rely on: not just Cloudflare, but also your hosting, databases, email providers, and payment services. It makes sense to directly monitor Cloudflare's official status page and cross-reference the information with real user reports, instead of relying solely on internal perception.
Sponsored Protocol
Right after comes the strategic part. Every serious project should ask itself: what happens if our CDN or DNS provider disappears for a few hours? Do we have a way to failover? Are we able to communicate quickly with customers when the problem is not ours but the downstream infrastructure's? Technical realities like Meteora Web think exactly about this: never take any layer of infrastructure for granted as infallible, and build solutions that can degrade gracefully instead of shutting down abruptly.
Today's Cloudflare outage is yet another sign of the fragility of an Internet that rests on a few large nodes. For those who live in the digital world, the message is simple and uncomfortable: it's not enough to choose a big name and feel safe. You need to understand how the chain that takes a user from the address bar to your site really works, and consciously decide how much of that chain you want to control and how much you are willing to delegate.